by Andrew Cochran
December 30, 2018
updated October 2019
It’s confusing when terms mean the same thing — but only some of the time. Artificial intelligence, machine learning, and deep learning are often used interchangeably. In one way, they are the same:
- Machine learning is a kind of artificial intelligence
- Deep learning is a kind of machine learning — so, it’s also a kind of AI
But not all of AI is achieved with machine learning, And, not all of machine learning uses deep learning.
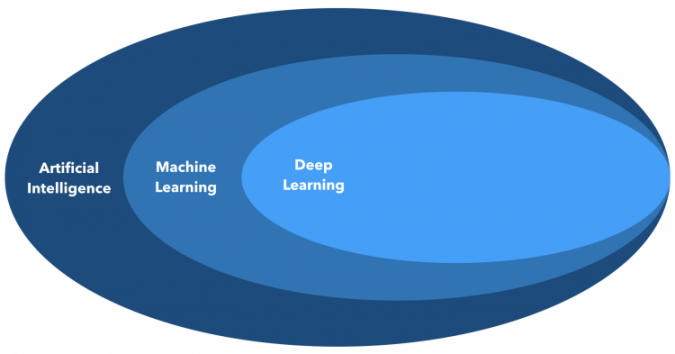
Here’s a way to set them apart:
Artificial intelligence is a result — the way we think of a computer when it does a complex task as well as a human, like recognizing a face. When a computer produces a result comparable to a human doing the same task, it exhibits AI.
Machine learning is a way of acquiring data — different from computers that need written instructions in the form of a computer program (more below). ML systems exhibit AI after acquiring the data in a characteristic way.
Deep learning is a way of processing data — making more refined predictions using multiple processing layers. It’s the layers that connote ‘deep’ (more below). DL systems exhibit AI after using ML to acquire data and process it in a characteristic way.
Before machine learning: Computers learned by instructions written as code
Computers process data, so to operate, they need to acquire data. It used to be that words, numbers, images, colours — everything — were hand-coded in a form the computer could understand. The approach is called symbolic computing.
When using symbolic computing, every instruction is written in a logical structure; for example, if state A happens/exists, then do thing 1. These are known as ‘if-then’ statements. Vast numbers are required for complex operations. They are written in computer code, together forming computer programs. Writing computer programs so that they had the fewest instructions to reach the desired outcome became an art, generally known as computer programming, or coding, for short.
With machine learning: Computers learn by example
The breakthrough of machine learning was that computers could reach outcomes without explicit programs and instead based on representative data. Instead of coding every feature of, say, a car, machine learning systems are shown images of cars, by the thousands or millions, each labelled as ‘car.’ From this volume of representative images, machine learning systems develop a model of what constitutes ‘a car.’ Altogether, these form what’s called the training set.
After training is complete, when the system sees a new image, it will predict it is ‘a car’ when the features fit the model formed by the system for ‘car.’
The same principles apply to sounds, words, or other kinds of data. The most important factors are that (a) there is a plentiful supply of examples for the training set, and (b) each piece of data in the training set is labelled accurately. Machine learning removes the need for precise instructions, which can be laborious and sometimes impossible, given the number of potential states that need to be anticipated.
Yet machine learning presents new difficulties. Current systems need massive amounts of data to achieve accuracy. This is compounded by the need to have them labelled for use in many forms of machine learning. So if a training set has, say, 300,000 images, each one needs to be labelled and identified with as much precision as possible.
In deep learning: ‘Deep’ is about the way data is processed
Deep learning uses multiple layers to interpret the data and predict meaning. Each layer refines the analysis. A crude metaphor is like using many filters or lenses to achieve greater clarity. The deep learning process is inspired by the way human neurons work in the brain, so deep learning is said to use a neural network.
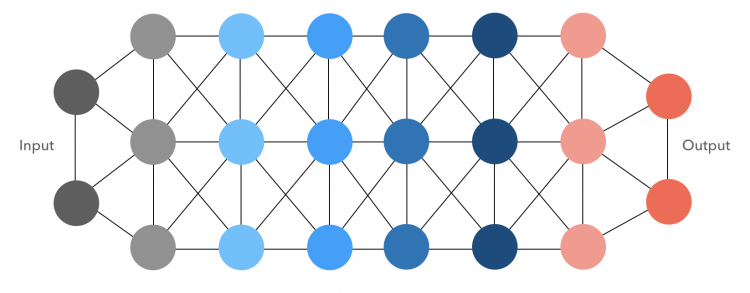
Neural networks may have any number of neurons and layers. The more nuanced analysis made possible by deep learning helps achieve levels of prediction that are the same or better than by humans, for example, in visual recognition.
Some deep learning systems go a step further and don’t require the data to be labelled. These more advanced forms of neural networks figure out similarities and group features together in clusters. With iterative processing through the neural network, they can figure out the patterns in an unlabelled training set and then form a model.
These two different ways that machine learning systems learn are known as supervised learning (using labels) and unsupervised learning (no labels). A third type of learning for neural nets is called reinforcement learning. We have an explainer that goes into more detail about these forms of learning. See How Do Algorithms Work?
Uses vary by data and need
Here are some examples of machine learning and deep learning now seen in everyday use:
| Capability | Example |
| Face recognition | Unlocking mobile devices, access to secure premises |
| Voice recognition | Alexa, Google Home, Siri |
| Recommedations | E-commerce catalogues, video choices, music services |
| Filtering | Spam detection, custom feeds |
| Resolving destinations | The fastest traffic route under current conditions, predicting ride-sharing options |
| Enquiries | Chatbots |
Learning-based systems are appropriate when working with very large quantities of data. They need plentiful data to function well. Some journalists are beginning to use machine learning systems to find patterns in very large data sets, for example, in investigative projects. There also is work going on to spot trends in very large data sets, such as aggregated tweets.
Many AI tools used in journalism are still achieved with symbolic computing, the original form of AI. First, data sets used in journalism work often involve smaller data sets. Codewriting makes sense when working without huge volumes. Second, once the code is error-free, it will produce the same outcome every time, meaning it can work with a high degree of reliability. Third, the data and the factors contributing to the conclusion reached are completely traceable, enabling verification of the results.
Related
- AI in the newsroom | Three examples of machine learning in the newsroom | GEN
- AI in the newsroom| Quartz forms AI studio | DIGIDAY
- Explainer talks | How we teach computers to understand pictures | TED
- Video | panels/talks | Andrew Ng: Artificial Intelligence is the New Electricity
- Explainer | How do algorithms work?
- Explainer | How is artificial intelligence used in journalism?